
El jueves, los investigadores de Microsoft anunciaron un nuevo modelo de IA de texto a voz llamado VALL-E que puede simular de cerca la voz de una persona cuando se le da una muestra de audio de tres segundos. Una vez que aprende una voz específica, VALL-E puede sintetizar el audio de esa persona diciendo cualquier cosa, y hacerlo de una manera que intente preservar el tono emocional del orador.
Sus creadores especulan que VALL-E podría usarse para aplicaciones de texto a voz de alta calidad, edición de voz donde una grabación de una persona podría editarse y cambiarse de una transcripción de texto (haciéndolos decir algo que originalmente no hicieron), y creación de contenido de audio cuando se combina con otros modelos de IA generativa como GPT-3.
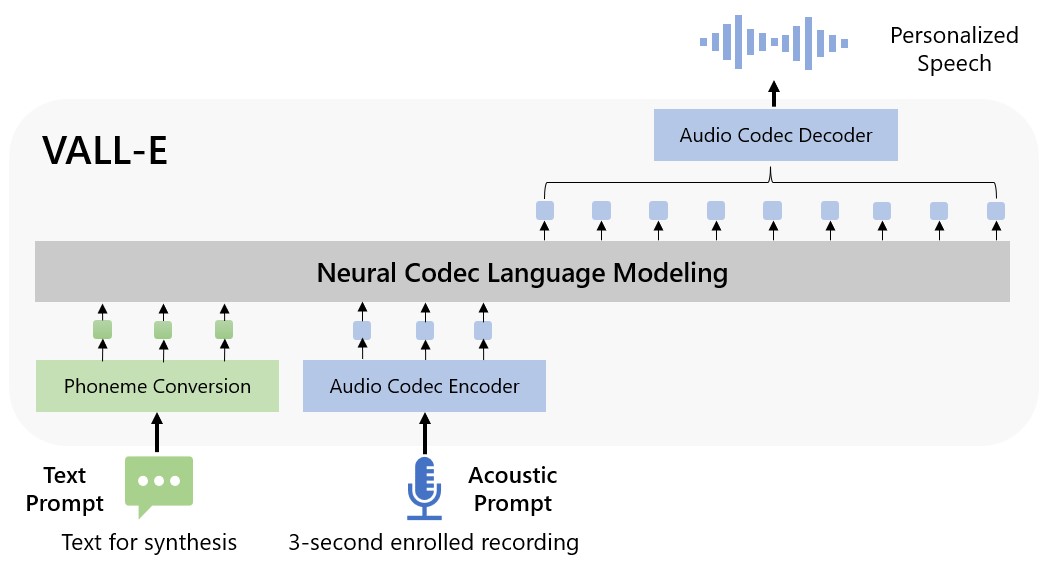
Microsoft llama a VALL-E un «modelo de lenguaje de códec neural», y se basa en una tecnología llamada EnCodec, que Meta anunció en octubre de 2022. A diferencia de otros métodos de texto a voz que normalmente sintetizan el habla manipulando formas de onda, VALL-E genera códigos de códec de audio discretos a partir de texto y indicaciones acústicas. Básicamente analiza cómo suena una persona, divide esa información en componentes discretos (llamados «tokens») gracias a EnCodec, y utiliza datos de entrenamiento para hacer coincidir lo que «sabe» sobre cómo sonaría esa voz si dira otras frases fuera de la muestra de tres segundos. O, como Microsoft lo pone en el documento de VALL-E:
Para sintetizar el habla personalizada (por ejemplo, TTS de disparo cero), VALL-E genera los tokens acústicos correspondientes condicionados a los tokens acústicos de la grabación inscrita de 3 segundos y el aviso de fonema, que restringen la información del altavoz y el contenido, respectivamente. Finalmente, los tokens acústicos generados se utilizan para sintetizar la forma de onda final con el decodificador de códec neuronal correspondiente.
Microsoft entrenó las capacidades de síntesis de voz de VALL-E en una biblioteca de audio, ensamblada por Meta, llamada LibriLight. Contiene 60.000 horas de habla en inglés de más de 7.000 hablantes, en su mayoría de audiolibros de dominio público de LibriVox. Para que VALL-E genere un buen resultado, la voz en la muestra de tres segundos debe coincidir estrechamente con una voz en los datos de entrenamiento.
En el sitio web de ejemplo de VALL-E, Microsoft proporciona docenas de ejemplos de audio del modelo de IA en acción. Entre las muestras, el «Speaker Prompt» es el audio de tres segundos proporcionado a VALL-E que debe imitar. La «Verdad del suelo» es una grabación preexistente de ese mismo orador que dice una frase en particular con fines de comparación (más o menos como el «control» en el experimento). La «línea de base» es un ejemplo de síntesis proporcionada por un método convencional de síntesis de texto a voz, y la muestra «VALL-E» es la salida del modelo VALL-E.
Mientras usaban VALL-E para generar esos resultados, los investigadores solo Alimentaron la muestra de tres segundos «Speaker Prompt» y una cadena de texto (lo que querían que dijera la voz) en VALL-E. Así que compara la muestra de «Verdad del suelo» con la muestra de «VALL-E». En algunos casos, las dos muestras están muy cerca. Algunos resultados de VALL-E parecen generados por ordenador, pero otros podrían confundirse con el habla humana, que es el objetivo del modelo.
Además de preservar el timbre vocal y el tono emocional de un orador, VALL-E también puede imitar el «entorno acústico» del audio de muestra. Por ejemplo, si la muestra proviene de una llamada telefónica, la salida de audio simulará las propiedades acústicas y de frecuencia de una llamada telefónica en su salida sintetizada (esa es una forma elegante de decir que también sonará como una llamada telefónica). Y las muestras de Microsoft (en la sección «Síntesis de la diversidad») demuestran que VALL-E puede generar variaciones en el tono de voz cambiando la semilla aleatoria utilizada en el proceso de generación.
Tal vez debido a la capacidad de VALL-E para alimentar potencialmente travesuras y engaños, Microsoft no ha proporcionado código VALL-E para que otros experimenten, por lo que no pudimos probar las capacidades de VALL-E. Los investigadores parecen ser conscientes del posible daño social que esta tecnología podría traer. Para la conclusión del artículo, escriben:
«Dado que VALL-E podría sintetizar el habla que mantiene la identidad del hablante, puede conllevar riesgos potenciales en el mal uso del modelo, como suplantar la identificación de voz o hacerse pasar por un hablante específico. Para mitigar tales riesgos, es posible construir un modelo de detección para discriminar si un clip de audio fue sintetizado por VALL-E. También pondremos en práctica los Principios de IA de Microsoft cuando desarrollemos aún más los modelos».
